

ADVERTISEMENT
Filtered By: Hashtag
Hashtag
Twitter study maps the 'superdialects' of the wired world
+
Make this your preferred source to get more updates from this publisher on Google.
In an attempt to map the global spectrum of Spanish dialects, a pair of linguistic researchers from Europe analyzed millions of geotagged tweets— and discovered "superdialects."
A dialect is a particular iteration of language whose use is associated with a specific social group or region. Dialects are of interest to researchers because they draw attention to social interactions between different groups and how they influence one another. In the past, research and study of dialects has been limited by brute force data gathering. The linguistic atlases that researchers create are limited by the number of people they can interview and survey regarding their lingual character.
Bruno Gonçalves of the University of Toulon in France and David Sanchez at the Institute for Cross-Disciplinary Physics and Complex Systems in Majorca, Spain found that Twitter provided a surprisingly efficient medium to capture the use of dialects and their distribution. The global social media service provided access to millions of tweets written in Spanish. In the study, entitled, "Crowdsourcing Dialect Characterization Through Twitter," Gonçalves and Sánchez sampled the fraction of those tweets that were posted over the past two years and contained geolocation information.
50 million tweets
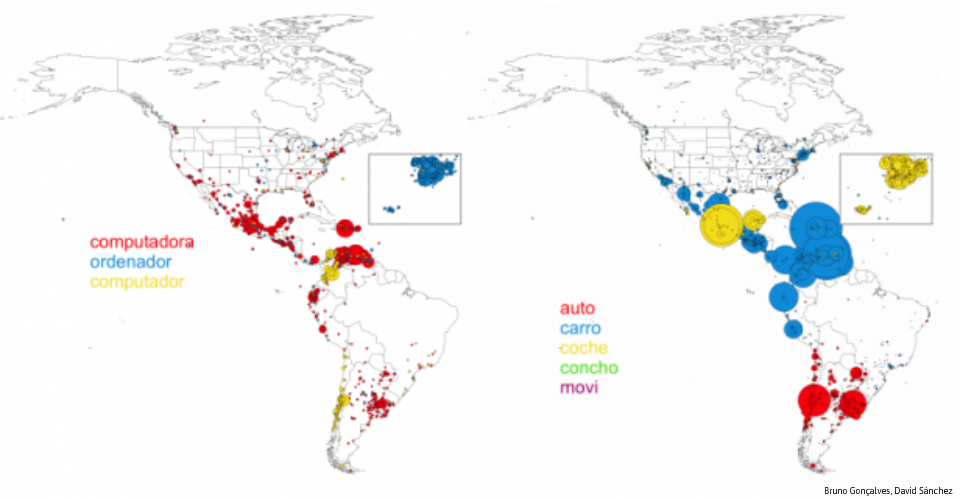
All told, they created a database of 50 million geolocated Spanish tweets, mostly from Spain, Spanish America and the United States. They then looked for word variations indicative of specific dialects and plotted where different words were being used. For example, the word car in Spanish can be auto, automóvil, carro, coche, concho, or movi; variations on computer include computador, computadora, microcomputador, microcomputadora, ordenador, or PC. Individual variations are more common in certain dialects than others.
Gonçalves and Sánchez geographically mapped the distribution of dialects, and found that Spanish dialects can be organized in two major groups the authors call “superdialects."
Thanks to globalization induced language homogenization, one of these emerging superdialects is predominant to major Spanish and American cities across the world. Designated Superdialect α, it's akin to a Spanish International, whose spread is hastened by the Internet.
Superdialect β
The other superdialect — Superdialect β — is almost exclusive to rural communities. A machine learning algorithm found subclusters within this group and discovered three different variations corresponding to a dialect used in Spain, a Caribbean and Latin American dialect and another variation used exclusively in South America. This ostensibly reflects settlement patterns of Spanish immigrants from centuries past.
“Conquerors and settlers occupied first the territories of Mexico, Peru and the Caribbean, and only much later colonists established permanent residence in [South America], which stayed away from prestigious linguistic norms," Gonçalves and Sánchez write. “This strong cultural heritage that can still be observed, centuries later, in our datasets deserves to be further analyzed in future works,” he said.
Limitations to crowdsourcing
Limitations to crowdsourcing
This study is not the first time that researchers have used social media for crowdsourced data gathering. However, Gonçalves and Sánchez warn that there are limitations to not just how far Twitter can go in studying language, but where.
Some languages, such as Mandarin, have a limited presence on the platform making potential study difficult. Still, computational linguistic techniques remain promising in future research, as they demonstrate how modern forms of communication can reveal patterns that were previously difficult to document. — TJD, GMA News
Some languages, such as Mandarin, have a limited presence on the platform making potential study difficult. Still, computational linguistic techniques remain promising in future research, as they demonstrate how modern forms of communication can reveal patterns that were previously difficult to document. — TJD, GMA News
